传DeepSeek自研芯片,厂商们要把AI成本打下来
电子发烧友网报道(文/黄晶晶)日前业界消息称,传DI成DeepSeek正广泛招募芯片设计人才,研芯加速自研芯片布局,片厂其芯片应用于端侧或云侧尚不明朗。商们不少科技巨头已有自研芯片的把A本打动作,一方面是传DI成自研芯片能够节省外购芯片的成本,掌握供应链主动权,研芯另一方面随着AI推理应用的片厂爆发,AI推理芯片有机会被重新定义。商们
DeepSeek不完全依赖英伟达
去年12月底发布的把A本打DeepSeek-V3模型,整个训练使用2048块英伟达H800 GPU。传DI成H800是研芯英伟达特供中国显卡,相较于它的片厂旗舰芯片H100降低了部分性能。也就是商们说DeepSeek-V3模型的训练并不需要追求使用最尖端的GPU。
DeepSeek在训练过程中采用了多种方法来优化硬件利用效率。把A本打例如,通过绕过CUDA编程框架,直接使用英伟达的中间指令集框架Parallel ThreadExecution (PTX),DeepSeek能够更高效地利用硬件资源,提供更细粒度的操作控制,从而避免由于CUDA的通用性导致的训练灵活性损失。这种做法使得DeepSeek能够在五天内完成其他模型需要十天才能完成的训练任务,极大地提高了训练效率。
DeepSeek的V3和R1大模型得到了不少芯片厂商的适配。如1月25日AMD宣布将DeepSeek-V3模型集成到其Instinct MI300X GPU上。而适配DeepSeek-R1大模型的厂商包括英伟达、英特尔以及国内厂商昇腾、龙芯、摩尔线程、海光信息等等。而采用这些芯片所获得的DeepSeek-R1模型推理性能不亚于英伟达GPU的效果。
DeepSeek有着对架构更深层次的理解,如若自研芯片,发挥其软硬件结合的能力,那么研发更具性价比的训练或推理芯片,进一步降低成本,或许将在更大程度上促进端侧AI的应用爆发,以及带动AI芯片的多样性发展。
OpenAI 3nm 推理芯片
去年,OpenAI进行硬件战略调整,旨在优化计算资源和降低成本。OpenAI将引入AMD的MI300系列芯片,并继续使用英伟达的GPU。而其自研芯片也提上日程。去年10月,OpenAI与芯片制造商博通合作开发首款专注于推理的人工智能芯片。双方还在与台积电进行磋商,以推进这一项目。
据外媒最新报道OpenAI 将在未来几个月内完成其首款内部芯片的设计,并计划将其送往台积电制造,台积电将使用 3nm 技术制造 OpenAI 芯片,该芯片有望在 2025 年底进行测试以及在 2026 年开始大规模生产,预计该芯片将具有“高带宽内存”和“广泛的网络功能”。
根据机构测算,到2028年人工智能的推理负载占比有望达到85%,考虑到云端和边缘侧巨大的推理需求,未来推理芯片的预期市场规模将是训练芯片的4~6倍。OpenAI自研推理芯片正好赶上这波人工智能推理应用的全面爆发。
亚马逊3nm制程Trainium3芯片
实际上,为了摆脱对英伟达GPU的依赖,亚马逊、微软和 Meta 等科技巨头也开始自研芯片。
去年12月,亚马逊 AWS 宣布,基于其内部团队所开发 AI 训练芯片 Trainium2 的 Trn2 实例广泛可用,并推出了 Trn2 UltraServer 大型 AI 训练系统,同时还发布了下代更先进的 3nm 制程 Trainium3 芯片。
单个 Trn2 实例包含 16 颗 Trainium2 芯片,各芯片间采用超高速高带宽低延迟 NeuronLink 互联,可提供 20.8 petaflops 的峰值算力,适合数 B 参数大小模型的训练和部署。
而亚马逊 AWS下代 Trainium3 AI 训练芯片,是 AWS 首款采用 3nm 制程的芯片产品。亚马逊表示基于 Trainium3 的 UltraServer 性能可达 Trn2 UltraServer 的 4 倍,首批基于 Trainium3 的实例预计将于2025年底推出。
LPU语言处理单元
在AI推理大潮下,Groq公司开发的语言处理单元(Language Processing Unit,即LPU),以其独特的架构,带来了极高的推理性能的表现。
Groq的芯片采用14nm制程,搭载了230MB SRAM以保证内存带宽,片上内存带宽达80TB/s。在算力方面,该芯片的整型(8位)运算速度为750TOPs,浮点(16位)运算速度为188TFLOPs。
在Llama 2-70B推理任务中,LPU系统实现每秒近300 token的吞吐量,相较英伟达H100实现10倍性能提升,单位推理成本降低达80%。在Llama 3.1-8B推理任务中,LPU系统实现每秒736 token的吞吐量。
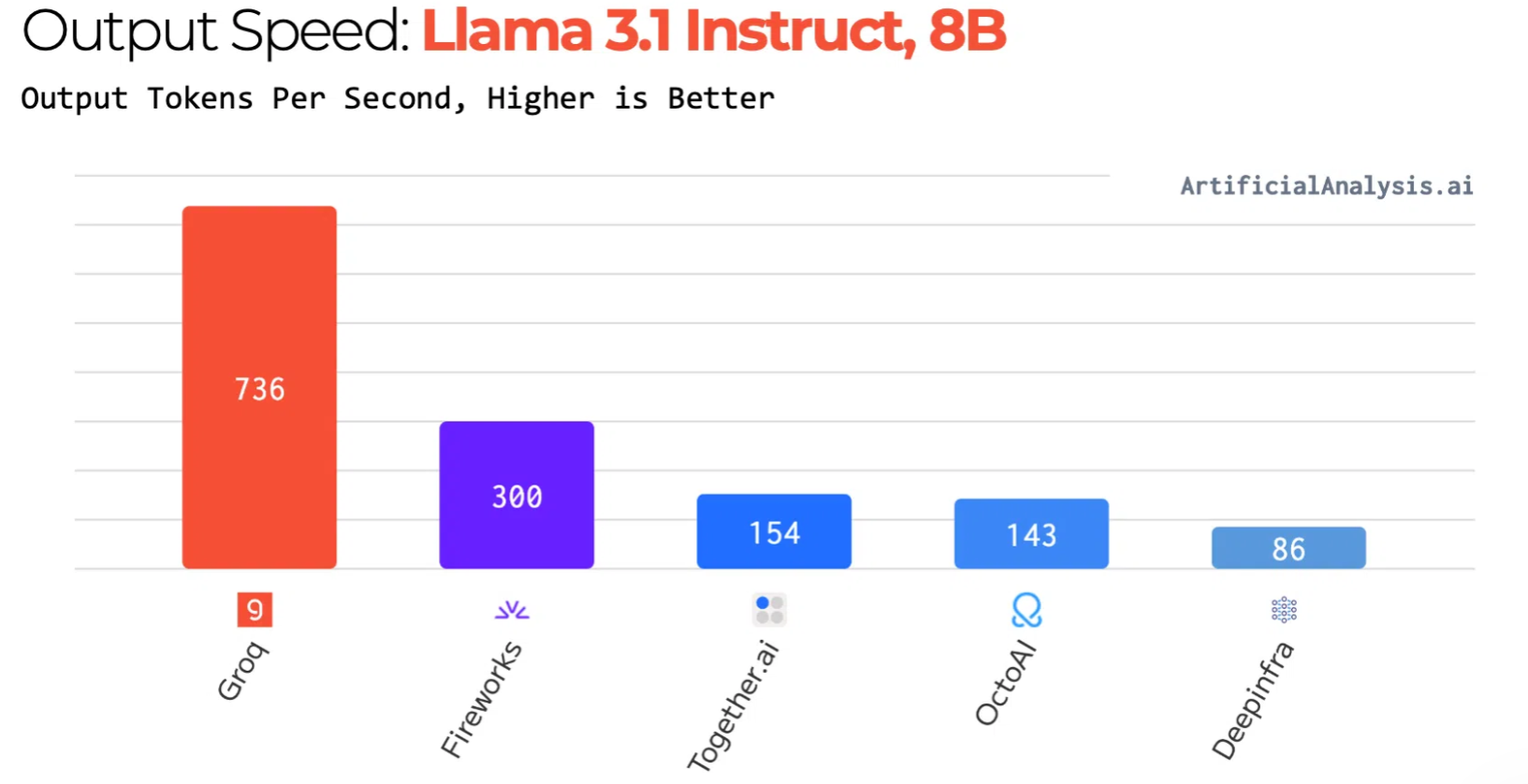
图源:Groq官网
公开信息显示,LPU的运作方式与GPU不同,它使用时序指令集计算机(Temporal Instruction Set Computer)架构,与GPU使用的SIMD(单指令,多数据)不同。这种设计可以让芯片不必像GPU那样频繁地从HBM内存重载数据。并避免了HBM短缺的问题,从而降低成本。
在能效方面,LPU 通过减少多线程管理的开销和避免核心资源的未充分利用,实现了更高的每瓦特计算性能,在执行推理任务时,从外部内存读取的数据更少,消耗的电量也低于英伟达的GPU。
LPU的推出为AI推理芯片带来了新的思路,但不得不说的是,Groq LPU芯片的成本相对较高,主要是购卡成本和运营成本。若以大模型运行吞吐量来计算,同等数据条件下,Groq LPU的硬件成本价格不菲。尽管这一芯片的性能表现突出,但对于成本优化还需要做出很多努力。希望随着硬件技术、生产制造以及规模效应的逐步成熟,其应用成本有望得到改善。
DeepSeek的出现,以低成本特性降低了企业准入门槛,使更多企业能够开展 AI 项目,推理端需求大幅增长。但这还不够,要使AI训练或推理成本进一步下探,不再局限于采用某一家的GPU,而是SoC、ASIC、FPGA等芯片都有机会,一些新的技术架构、不依赖先进工艺的芯片等有更多发展的空间,从而推动AI芯片的多元化发展。
热点关注
- 新零售、新渠道、新模式 优享智能照明2019全新启程
- 荣耀中国区CMO姜海荣将离职
- SemiQ推出1700 V SiC MOSFET系列,助力中压大功率转换领域
- 大数据是利是弊?给壁挂炉带来商机就是利!
- 消费市场变革 灯饰照明品牌变还是不变?
- 卡尔采夫:扎哈维是以色列头号球星,听说他在富力的工资非常高
- CMOS传感器在安防监控中的应用介绍
- 中国AI长卷(四):行业旷野
- 迎战3.15 取暖器十大品牌以诚信取胜
- 攻无不克战无不胜 比克电器团队的力量
- 面对市场变化 橱柜企业要学会做品牌口碑
- 新风系统VS空气净化器优劣比对
- 日本队晒战袋鼠海报:堂安律单人出镜,球队剑指开局四连胜
- 集成吊顶品牌众多 小编教你六招
- 维尼修斯社媒晒本泽马签名球衣:KB9
- QLC存储新里程:德明利探索高效存储之路,赋能数据时代新需求
- 著名古典家具品牌:改善市场营销 让消费者买到品质产品
- 谨慎应用价格“武器” 集成灶企业实现利润最大化
- 5解围!官方:费耶诺德后卫汉茨科当选米兰11费耶诺德全场最佳
- 德国球员欧战生涯前3球均攻破德甲球队,库恩是历史第3人